实习面经-腾讯一面、阿里一面
实习面经
—————————腾讯一面
水平触发和边缘触发的区别
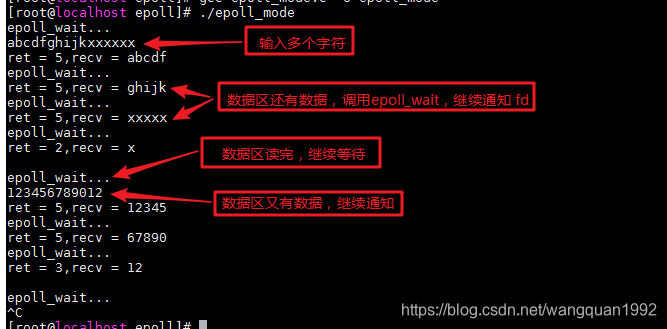
水平触发是当缓冲区有数据时会一直读,当缓冲区可以写入时会一直写入
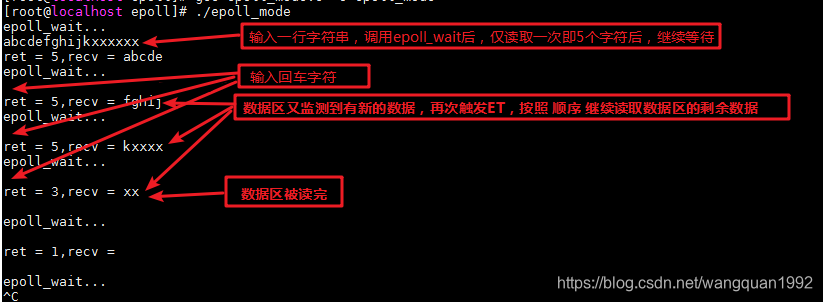
边缘触发是当缓冲区从空到非空时会发送读取信号,缓冲区从满到不满时会发送写信号
下面有两个直观的例子
水平模式下:
边缘模式下:
而且在accept接收连接时,add_event(this->epollfd, c->socketfd, EPOLLIN | EPOLLET);
这里的socket和读写数据的socket是不同的socket,新的连接到来时设置为边缘触发,并触发一次读事件EPOLLIN
一般情况边缘模式更有效率,因为水平模式会有惊群效应,遍历每个socket时,只要里面有数据就会触发读,而边缘模式会等到下一次事件到来才会触发读
类的多态实现、继承
多态是利用虚函数实现的,每个类会维护一个虚函数表,对一个对象取地址就可以获取虚表指针,例如&obj
继承的话,有公有继承,私有继承和保护继承,公有继承会继承父类的公有和保护方法并保留其原有属性;私有继承会继承父类的公有和保护方法,并作为私有成员;保护继承会继承公有和保护方法并作为保护成员。
编译顺序
有预处理,汇编,编译,链接
说说多线程
关于多线程的所有东西,包括多线程概念、线程池设计、锁在另一篇文章里[]
说说对协程的理解
协程也被叫做轻量级线程或者用户态线程,但实际上和线程还是有区别的.可以想象在单核下运行线程的机制,线程在CPU不停切换达到并发.而协程就是类似的情况
协程的本质是函数,但是函数运行时可以中断,然后切到别的协程函数运行,之后还可以恢复运行,但是多个协程还是运行在一个线程里的,所以协程不需要锁,共用同一个线程的资源,而且是同步阻塞的
epoll和select的区别
select是用fd_set保存所有文件描述符,fd_set是一个二进制集合,第几个fd就绪,第几个位就是1,否则置0. 调用select时会把fd_set拷贝进内核,然后遍历,如果有fd就绪的话,就修改fd_set,然后返回给用户态,用户再遍历一次fd_set
可以看到select的缺点很明显,内核和用户拷贝fd_set是很消耗性能的,而且采用的是遍历的方法,效率很低;同时select只支持1024个fd
epoll 有以下几个特点:
- 使用红黑树存储文件描述符集合
- 使用队列存储就绪的文件描述符
- 每个文件描述符只需在添加时传入一次;通过事件更改文件描述符状态
epoll 模型使用三个函数:epoll_create、epoll_ctl 和 epoll_wait
epoll_create 会创建一个 epoll 实例,同时返回一个引用该实例的文件描述符,epoll实例包含两个结构:
- 监听列表:底层红黑树,保存所有fd
- 就绪列表:底层链表,保存就绪的fd
epoll_ctl 会fd 添加到 epoll 实例的监听列表里,同时为 fd 设置一个回调函数,并监听事件 event。当 fd 上发生相应事件时,会调用回调函数,将 fd 添加到 epoll 实例的就绪队列上。
epoll_wait这是 epoll 模型的主要函数,功能相当于 select,主要是传入epoll_fd
epoll的优点是使用红黑树存储,效率高,而且每个fd设置回调函数,自动响应事件,不需要遍历,同时避免了内核和用户态频繁拷贝fd_set,只在epoll_ctl传递一次epoll_fd,后面不用再传递
还有个poll和select类似,但是poll使用的是链表存储fd
动态库和静态库
可以先说一下链接原理,无非就是预处理,汇编,编译,链接
动态库和静态的主要区别是在链接阶段,静态库是将所有的代码拷贝进可执行文件,而动态库只拷贝一些链接相关的东西,所以动态库较小,
然后在运行时动态库是运行时进行链接加载,而静态库加载很快,因为它已经包含了所有代码
静态库在编译完成后就可以不需要了,但是动态库一直需要存在
跳台阶高级
有个公式f[i]=2*f[i-1]
或者是f[i]=2^(n-1)
—————————阿里一面
说说TCP拥塞控制和流量控制
首先流量控制解决的问题是发送方发送能力和接收方接收能力不平衡的情况,如果接收方缓冲区满了,而发送方还在一直发送的话,会丢包,所以在接收方维护一个窗口,通过报文发送,发送方接收到这个窗口大小后,调整自己的发送窗口,不大于接收窗口大小
拥塞控制只要是避免发送方一直发送数据导致占满整个网络的问题,因为当网络拥堵时,有可能会丢包重传,发送方会一直发送导致网络更拥堵.
拥塞控制主要有四个算法:
- 慢启动算法:随着确认的ACK数+1,确认2个就cwnd+2,呈指数型增长
- 拥塞避免算法:设置阈值ssthresh,当cwnd超过这个值时,cwnd呈线性增长
- 拥塞发生算法有:超时重传和快重传
- 超时重传,ssthresh 设为 cwnd/2, cwnd 重置为 1
- 快重传,cwnd 设为 cwnd/2, ssthresh 重置为 cwnd
- 快恢复算法:快恢复和快重传一般一起使用,在快重传更新cwnd和ssthresh之后,cwnd=cwnd/2+3,这里的3时确认了的ACK,就是拥堵时接收到的数据量.而且当收到新数据之后,ssthresh恢复为最初拥堵时的值
TCP/IP五层协议
物理,数据链路,传输,网络,应用
问项目
hashmap底层
哈希表底层是数组加链表,数组下标由哈希函数确定,发生冲突时使用拉链法,将该值插入到链表后面
说说红黑树
红黑树是一颗特殊的树,它具有如下特点:
- 每个节点只有红色和黑色两种
- 根节点是黑色的, 叶节点是黑色的空值NULL
- 根节点到叶节点的黑色节点个数相同
- 根节点到叶节点,不会出现连续的红色节点
红黑树的插入,删除和查找就不展开说了
说说快排
快排的基本思想就是使用两个指针,然后定义一个哨兵,一般为首元素,然后从右向左找第一个比哨兵小的,从左向右找第一个比哨兵大的,然后交换这两个值,最后再交换哨兵和最后位置的值.
然后快排的事件复杂度平均为O(n),最坏情况下为O(n2),具体实现在所有排序
说说堆排
对一个数组堆排序的过程可以分为两步,首先建堆,从最后一个非叶子结点开始(n/2-1)进行调整;然后是另一轮调整,从最后一个节点开始向前到1,交换第0个节点和第i个节点,然后调整.
堆排的事件复杂度都是O(logn)